기술통계 - 표본의 분석
1. 평균
전체를 아우르는 값. 모든 데이터를 반영하기때문에 가장 쉽게 쓰이는 값. 통계에서는 Mean 으로 쓴다.
단점 : 아웃라이어같은 존재에 쉽게 값이 훼손되기 때문에 다른 분석값과 비교해봐야함
r 함수 : mean()
2. 중앙값
전체배열에서 중간에 있는 값. 아웃라이어에 훼손당하지 않음.
Median 이라고 쓴다. 자체에 의미보단 Mean 값을 보완하기 위해 쓰이는 경우가 많다.
r 함수 : median()
3. 범위값
최소 - 최대를 봄. 아웃라이어에 훼손당하기 쉬워서 사분위 범위를 사용한다.
25% 50% 75% 100% 구간별로 (이때 % 는 중앙값을 구하는 방식과 같이 구함. 순서대로 세우는 방식)
4분위 범위를 만든다. 이를 IQR 이라고 부르는데 Boxplot을 이용해 표시하면
중앙값 + 아웃라이어를 동시에 확인할 수 있어서 많이 쓰임.
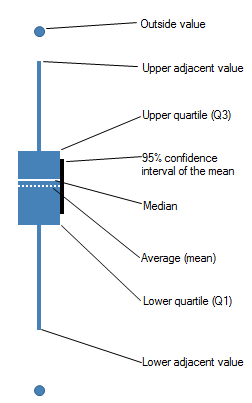 흔한 boxplot
흔한 boxplot
r 함수 : 범위값 range(); / 4분위 : quantile() / Boxplot : boxplot();
4. 산포도
분산 : 모든 데이터의 평균과의 차이의 제곱의 합. s제곱으로 표기함.
표준편차 : 분산의 제곱근. 제곱근을 해주는 이유는 단위의 형평성을 위해. (제곱하면 너무 값이 커짐) s 로 보통 표기함.
r 함수 : 분산 var() / 표준편차 sd()
5. 자유도
표본표준편차는 1/n 이 아니라 1/(n-1) 을 사용하는데 이는 표본과 모집단의 성질때문이다.
표본의 평균을 모집단과 맞추기 위해 n-1 개만 뽑고 나머지 1개는 모집단 평균에 맞춰 뽑는다.
그래서 실제로 자유롭게 뽑은건 n-1 이고 1/(n-1) 을 자유도라고 부른다.
모집단평균은 1/n 사용해도 됨.
6. 표준화
기준을 0 점으로 맞춰서 비교하는 방식. 서로 다른 단위 혹은 범위의 표본집단을 비교하기 좋음.
R에서 표준값 구하는 함수를 통해 표본을 변환시킬 수 있음. 공식은 표준편차값과 표본평균값을 이용해 만듬.
예시 : 토익, 토플의 비교.
r 함수 : scale()
7. 변동계수
표준화와 비슷한데 분산도를 한눈에 알 수 있도록 표시하는 방식. 표준편차의 표준화라고 보면 편함.
어떤 집단의 표준편차를 말할 때는 항상 변동계수로 말하도록 하자.
r 함수 : sd()/mean()
8. 공분산
다변량 변수를 표시할 때 분산되는 정도를 뜻함. 상관관계를 파악하는데 보통 쓰임.
상관관계는 -1 ~ 1 값을 가지며 절대값이 1에 가까울 수록 상관관계가 크다고 할 수 있으며 0 은 무관하다고 보면 됨.
r 함수 : cor(x,y) 상관관계를 구함. cov(x,y) 공분산을 구함.
이는 모두 R 함수로 쉽게 구할 수 있다. 꼭 외워두자.